IREX - MLflow : comprendre la gestion du cycle de vie des modèles de Machine Learning
Découvrez dans cet article comment MLflow facilite le suivi des expérimentations, le versionnement des modèles et leur gouvernance tout au long du cycle de vie d'un projet de Machine Learning.
1. Introduction : pourquoi gérer le cycle de vie des modèles ?
2. Présentation générale de MLflow
3. Composants clés de MLflow
4. Architecture générale de MLflow
5. Avantages et limites de MLflow
6. Conclusion
7. Voir aussi
1. Introduction : pourquoi gérer le cycle de vie des modèles ?
Le développement d’un modèle de Machine Learning ne s’arrête pas à son entraînement. Dans un projet réel, les équipes réalisent plusieurs expérimentations en modifiant les données, les hyperparamètres ou les algorithmes utilisés.
Sans une méthode structurée, il devient difficile de comparer les modèles, de retrouver les meilleures configurations et de reproduire les résultats obtenus.
La gestion du cycle de vie des modèles devient donc essentielle pour assurer le suivi des expérimentations, le versionnement et la préparation au déploiement. C’est dans ce contexte que MLflow s’impose comme une plateforme de référence pour organiser et gouverner les modèles de Machine Learning.
2. Présentation générale de MLflow
MLflow est une plateforme open source développée par Databricks pour simplifier la gestion du cycle de vie des modèles de Machine Learning.
Contrairement à une bibliothèque d’apprentissage automatique, MLflow ne sert pas à entraîner des modèles. Son rôle consiste à organiser l’ensemble des activités entourant leur développement : suivi des expérimentations, gestion des versions, partage des modèles et préparation de leur déploiement.
La plateforme est indépendante des bibliothèques de Machine Learning. Elle peut être utilisée avec Scikit-learn, TensorFlow, PyTorch, XGBoost ou encore LightGBM. Grâce à cette indépendance, MLflow s’intègre facilement dans des projets existants sans imposer un framework particulier.
3. Les principaux composants de MLflow
MLflow repose sur quatre composants complémentaires couvrant les principales étapes du cycle de vie d’un modèle.
MLflow Tracking
MLflow Tracking permet d’enregistrer automatiquement les expériences réalisées. Chaque exécution peut stocker les paramètres utilisés, les métriques obtenues, les artefacts générés et le modèle entraîné.
MLflow Projects
MLflow Projects propose un format standardisé permettant d’empaqueter les projets afin d’en faciliter le partage et l’exécution.
MLflow Models
MLflow Models permet de sauvegarder les modèles dans différents formats compatibles avec plusieurs environnements de déploiement.
MLflow Model Registry
MLflow Model Registry assure la gestion des versions des modèles ainsi que leur transition entre les phases de développement, de validation et de production.
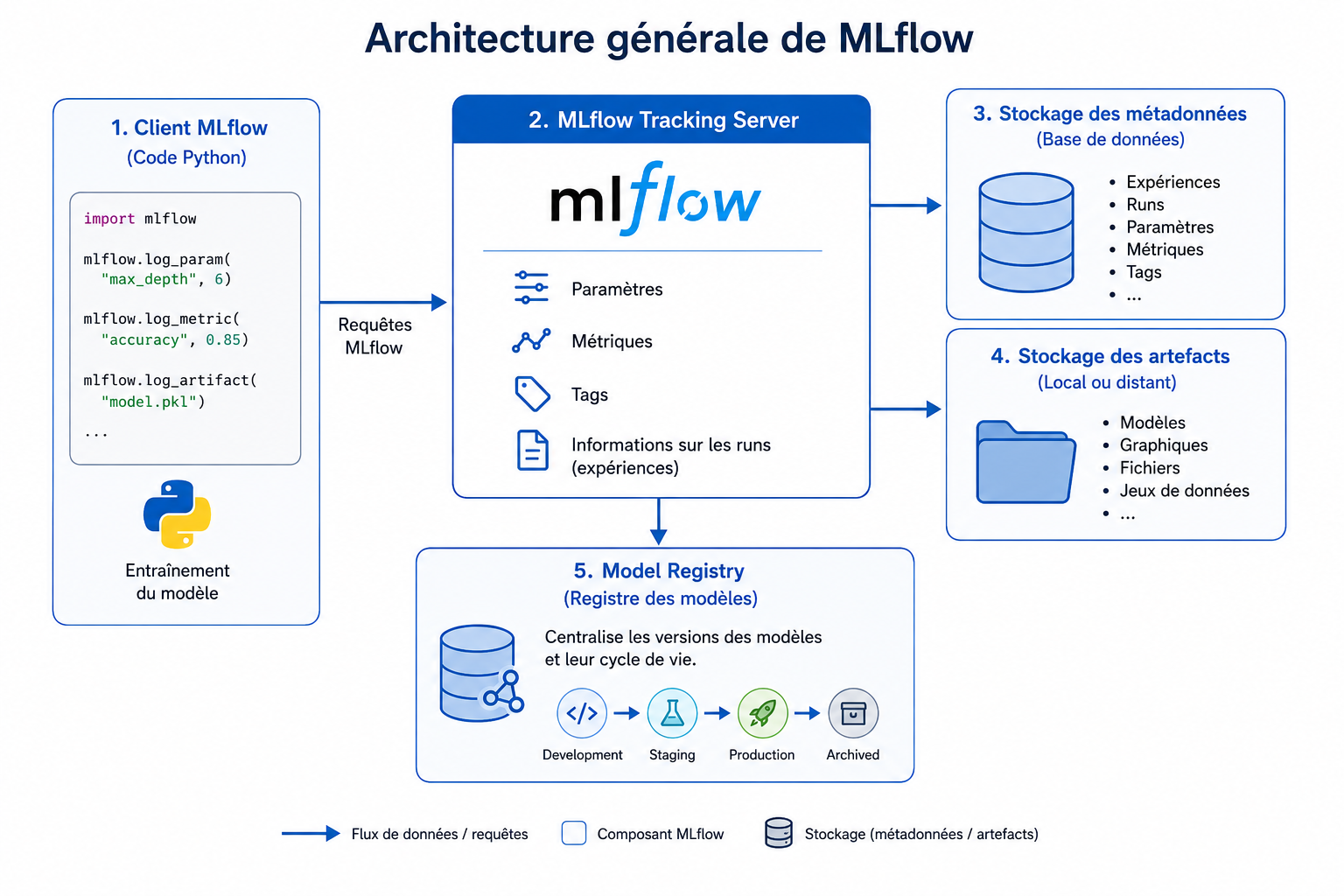
4. Architecture générale de MLflow
L’architecture de MLflow s’organise autour de plusieurs composants qui collaborent pour assurer le suivi des expérimentations et la gestion des modèles.
Le client MLflow est intégré dans le code Python utilisé pour entraîner les modèles. Il communique avec un Tracking Server, chargé d’enregistrer les paramètres, les métriques et les informations relatives aux expériences.
Les métadonnées sont conservées dans une base de données, tandis que les artefacts (modèles, graphiques, fichiers, jeux de données, etc.) sont stockés dans un espace de stockage dédié pouvant être local ou distant.
Le Model Registry vient compléter cette architecture en centralisant les différentes versions des modèles et leur cycle de vie.
5. Avantages et limites de MLflow
a) Avantages
| Avantage | Description |
|---|---|
| Open source | Aucun coût de licence. |
| Reproductibilité | Conservation des paramètres et des métriques. |
| Collaboration | Centralisation des expérimentations. |
| Compatibilité | Fonctionne avec Scikit-learn, TensorFlow, PyTorch et d’autres frameworks. |
| Versionnement | Gestion des différentes versions des modèles. |
b) Limites
| Limite | Description |
|---|---|
| Infrastructure | Certaines configurations nécessitent des ressources supplémentaires. |
| Sécurité | La gestion des accès doit être prise en compte. |
| Fonctionnalités avancées | Certains besoins MLOps nécessitent des outils complémentaires. |
| Courbe d’apprentissage | Une prise en main est nécessaire pour les équipes débutantes. |
6. Conclusion
Le développement d’un modèle de Machine Learning ne se résume pas à son entraînement. Il nécessite également un suivi rigoureux des expérimentations, une gestion efficace des versions et une organisation permettant de retrouver facilement les meilleures configurations.
Grâce à ses différents composants, MLflow répond à ces besoins en proposant une plateforme dédiée à la gestion du cycle de vie des modèles. Son approche favorise la reproductibilité des expériences, améliore la collaboration entre les équipes et facilite la gouvernance des modèles dans des environnements professionnels.
Le prochain article montrera comment utiliser concrètement MLflow pour suivre une expérience, enregistrer un modèle, gérer ses versions et préparer son déploiement dans un projet de Machine Learning.
No comments yet. Start a new discussion.