IREX - MLflow en pratique : de l’expérimentation au déploiement des modèles
Découvrez comment mettre en œuvre MLflow pour suivre vos expérimentations, enregistrer vos modèles, gérer leurs différentes versions et préparer leur déploiement.
1. Introduction
2. Installation et prise en main de MLflow
3. Suivi des expérimentations avec MLflow Tracking
4. Gestion et versionnement des modèles avec MLflow Model Registry
5. Cas d’utilisation en entreprise
6. Conclusion
7. Illustration Video
8. Voir aussi
1. Introduction
Dans un précédent article, nous avons présenté MLflow comme une plateforme permettant de gérer le cycle de vie des modèles de Machine Learning. Son rôle est de faciliter le suivi des expérimentations, le versionnement des modèles et leur préparation au déploiement.
Dans cet article, nous allons mettre en pratique ces concepts en découvrant comment installer MLflow, enregistrer une expérimentation, suivre les performances d’un modèle et gérer son cycle de vie jusqu’à sa mise en production.
2. Installation et prise en main de MLflow
MLflow peut être installé facilement dans un environnement Python. Une fois installé, il permet de suivre les expérimentations, d’enregistrer les modèles et de visualiser les résultats à partir d’une interface Web.
a) Installation
La commande suivante permet d’installer MLflow :
pip install mlflowUne fois l’installation terminée, il est possible de vérifier la version installée :
mlflow --versionb) Lancement de l’interface utilisateur
L’interface Web de MLflow peut être démarrée à l’aide de la commande suivante :
mlflow uiPar défaut, elle est accessible à l’adresse :
http://localhost:5000Cette interface permet de consulter les expériences enregistrées, de comparer les différentes exécutions, d’analyser les métriques obtenues et d’accéder aux artefacts générés.
c) Configuration d’un serveur de suivi
Dans un environnement collaboratif, MLflow peut être configuré avec :
- un Tracking Server centralisé ;
- une base de données pour les métadonnées ;
- un espace de stockage partagé pour les artefacts, comme Amazon S3, Azure Blob Storage ou un stockage compatible S3.
Cette architecture permet à plusieurs utilisateurs de partager les mêmes expérimentations et améliore la gouvernance des modèles.
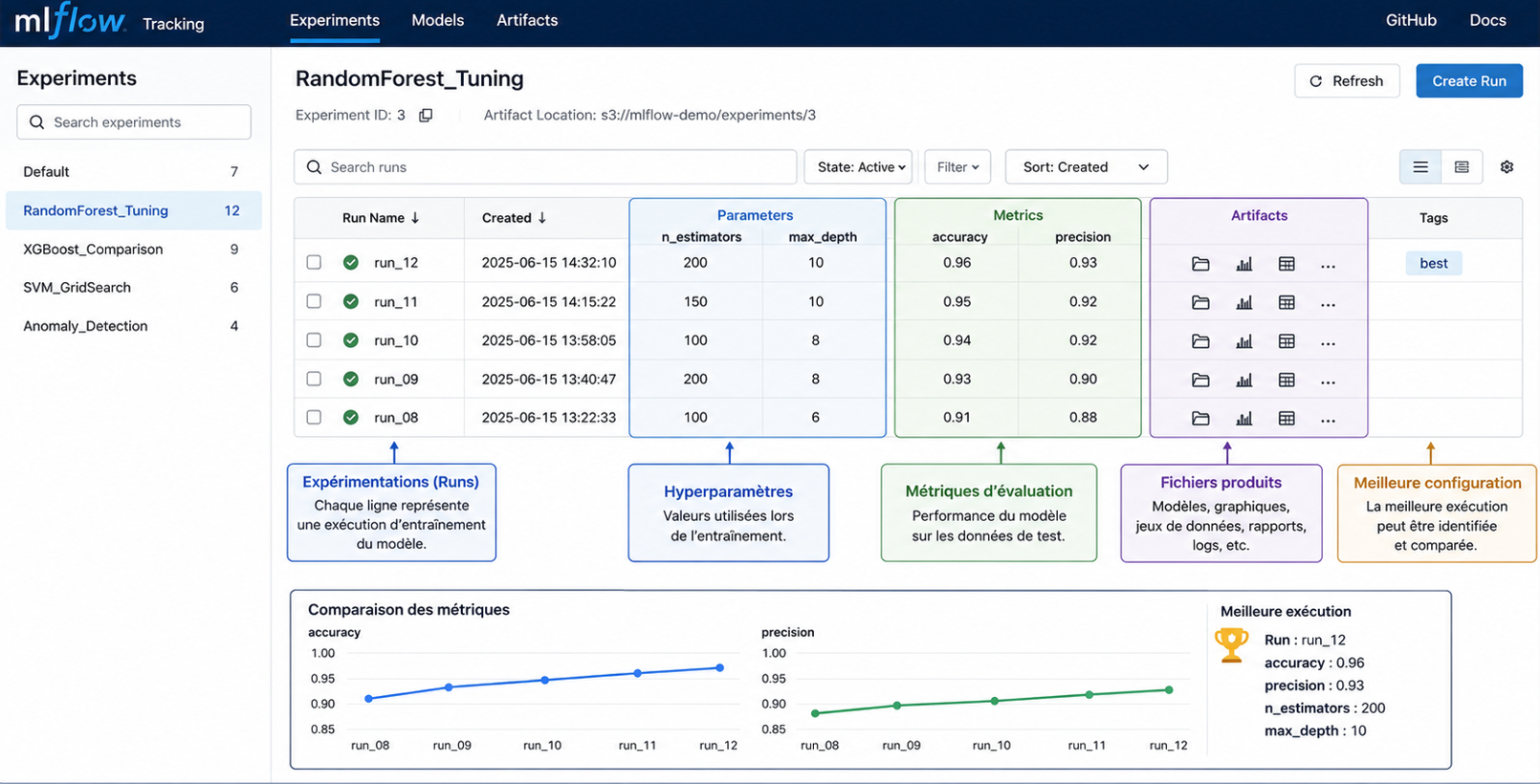
3. Suivi des expérimentations avec MLflow Tracking
Le composant MLflow Tracking permet d’enregistrer automatiquement les informations générées lors de l’entraînement d’un modèle.
Chaque expérimentation peut enregistrer :
- les hyperparamètres ;
- les métriques d’évaluation ;
- les modèles générés ;
- les fichiers produits, comme les graphiques, les jeux de données ou les rapports.
Par exemple :
import mlflow
with mlflow.start_run():
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 8)
mlflow.log_metric("accuracy", 0.94)
mlflow.log_metric("precision", 0.92)À chaque exécution, MLflow crée automatiquement une nouvelle expérience. Toutes les expériences deviennent consultables dans l’interface Web, où il est possible de comparer leurs performances.
Cette fonctionnalité facilite la reproductibilité des résultats et permet d’identifier rapidement les meilleures configurations.
4. Gestion et versionnement des modèles avec MLflow Model Registry
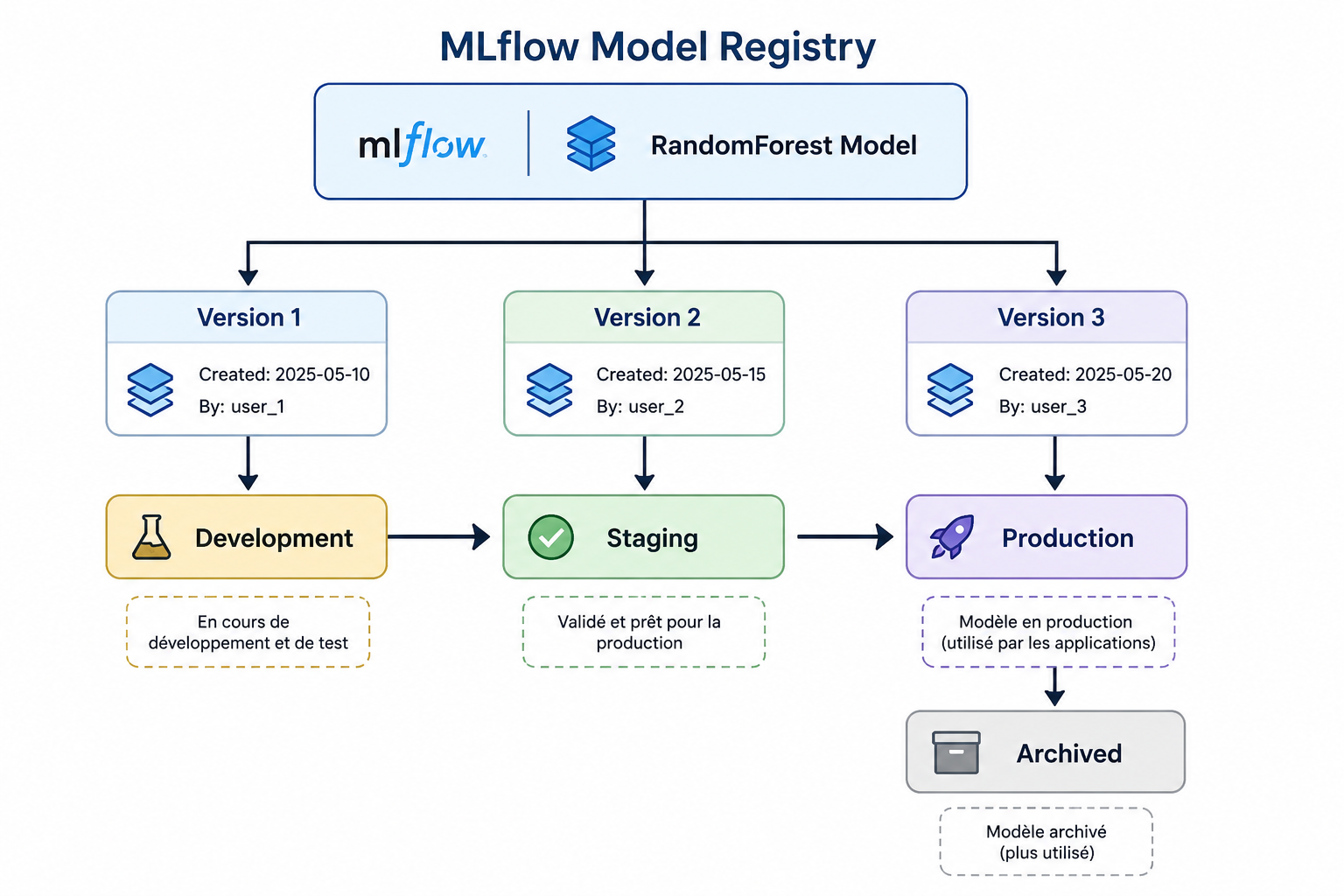
Une fois le meilleur modèle identifié, celui-ci peut être enregistré dans le Model Registry.
Le registre centralise toutes les versions d’un modèle et facilite leur gestion.
Un modèle peut évoluer selon plusieurs états :
- Development ;
- Staging ;
- Production ;
- Archived.
Par exemple :
import mlflow.sklearn
mlflow.sklearn.log_model(
model,
"RandomForest"
)Une fois enregistré, le modèle peut être promu vers l’environnement de Production après validation.
Le Model Registry permet ainsi de conserver l’historique complet des modèles et de contrôler leur évolution.
5. Cas d’utilisation en entreprise
Imaginons une entreprise souhaitant prédire le départ de ses clients, aussi appelé Customer Churn.
Plusieurs modèles sont entraînés :
- Régression logistique ;
- Random Forest ;
- XGBoost.
Chaque expérimentation est automatiquement enregistrée dans MLflow avec :
- les paramètres utilisés ;
- les métriques obtenues ;
- le modèle produit.
Les équipes peuvent ensuite comparer les résultats directement dans MLflow afin de sélectionner le modèle le plus performant.
Une fois validé, celui-ci est enregistré dans le Model Registry, puis promu vers l’état Production.
Cette approche améliore la collaboration entre les data scientists, garantit la traçabilité des expérimentations et facilite le déploiement des modèles.
6. Conclusion
MLflow accompagne les équipes tout au long du cycle de vie des modèles de Machine Learning.
Grâce à MLflow Tracking, les expérimentations sont enregistrées et comparées de manière structurée. Le Model Registry permet ensuite de gérer les versions des modèles et d’assurer leur gouvernance jusqu’à leur mise en production.
En combinant ces fonctionnalités, MLflow constitue aujourd’hui une solution incontournable pour mettre en œuvre une démarche MLOps fiable, reproductible et collaborative.
7. Illustration vidéo
Une démonstration vidéo peut illustrer les principales étapes de l’utilisation de MLflow :
- installation de MLflow ;
- lancement de l’interface Web ;
- enregistrement d’une expérimentation ;
- comparaison des métriques ;
- enregistrement d’un modèle ;
- gestion des versions dans le Model Registry.
No comments yet. Start a new discussion.